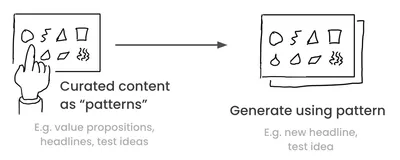
Leveraging patterns: pattern curation technique
5/9/2026
Pattern curation uses examples to steer model attention—few-shot style—for labels, tone, structure, and convergent outputs.
Read more → 5/9/2026
Pattern curation uses examples to steer model attention—few-shot style—for labels, tone, structure, and convergent outputs.
Read more →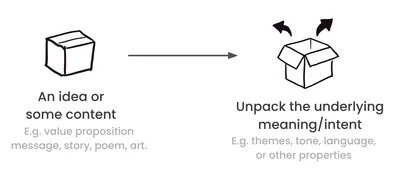
5/9/2026
Pattern extraction uses the model to analyse text and pull out themes, tone, assumptions, framing—and to stress-test ideas with structured critique.
Read more →
5/9/2026
General ways to use pattern-matching with language models—detect, identify, estimate, forecast, compare, discover, generate, and act.
Read more →
2/3/2026
Big Tech’s AI is a climate & ethical nightmare. But there is an alternative to using their AI models, and these alternatives actually work better...
Read more →
11/10/2025
Step-by-step guide to building AI workflows with n8n and your local Ollama model. No coding required. Published on Convert.
Read more →
10/27/2025
Set up one chat interface to compare local and cloud AI models side by side. Uses Open WebUI, Docker, Ollama, and OpenRouter. Published on Convert.
Read more →
10/13/2025
Expose your LLM as an API so other apps and workflows can use it. Covers LM Studio Developer Mode and Ollama in the terminal. Published on Convert.
Read more →
9/24/2025
How to get a tiny 0.6B model to match ChatGPT on messy user feedback—using “breakpoints” and splitting the task by sentiment. Published on Convert.
Read more →
9/10/2025
Why run small models on your own machine, and how to use LM Studio to find and test them on real tasks. Published on Convert.
Read more →
8/6/2025
What the “how many R’s in strawberry?” moment teaches us about LLMs—and five practical ways to use AI more clearly and responsibly. Published on Convert.
Read more →
6/26/2025
What AI hallucinations are, why they happen, and four practical ways to spot and manage them. Published on Convert.
Read more →
5/19/2025
Why “huge context” isn’t enough for text analysis—and simple ways to structure and filter your data so AI gives better, more reliable insights. Published on Convert.
Read more →
4/24/2025
Use one-shot and few-shot examples to steer attention, remove ambiguity, and get the format and tone you want. Published on Convert.
Read more →
3/26/2025
Share how you work with AI by naming “beats” (Query, Validate, Think, etc.) and chaining them into patterns—for research, brainstorming, and critique. Published on Convert.
Read more →
3/19/2025
A series teaching product owners, developers, and experimentation leads to use AI sustainably—from human–AI fundamentals and local/small models (LM Studio) to n8n workflows, MCP, and building your own chat interfaces.
Read more →
2/20/2025
Frameworks so AI supports your work instead of taking over—scaffolding, milestones, three modes of collaboration, and the Kolb learning cycle. Published on Convert.
Read more →1/22/2025
A visual guide to the stats you need for A/B tests—noise, standard deviation, z-scores, and p-values—so you can read results with confidence. Published on Convert.
Read more →
4/20/2022
Using simulations to answer when to run SRM checks, false-positive risk, optimal traffic for accuracy, and whether continuous monitoring increases Type I error. Published in Towards Data Science.
Read more →
7/22/2021
What SRM is, why it matters, and how to check it—with the Chi-squared test in Python and spreadsheets. Prioritise users over visits; check early and often. Published in Towards Data Science.
Read more →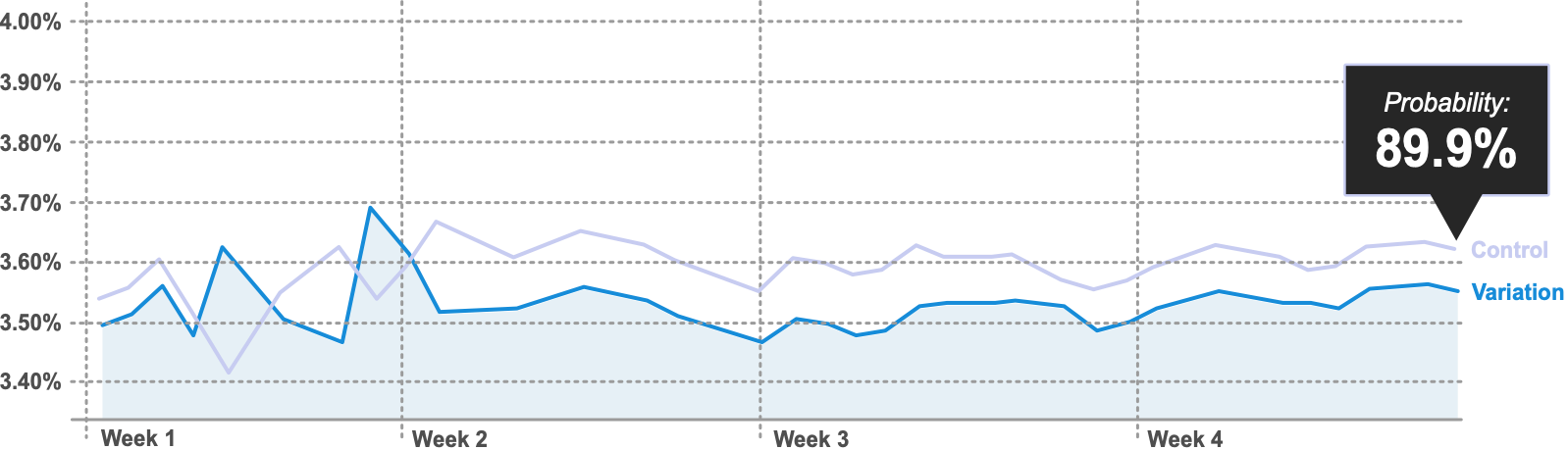
4/16/2021
A how-to for calculating Bayesian Expected Loss—the risk of choosing one variant over another—with Python, beta distributions, and rules for when to call a result. Published in Towards Data Science.
Read more →
3/2/2021
Telling the story of risk, reward, and certainty using the principles of comic panel transitions—and how Expected Loss adds a clearer, more actionable view. Published in Towards Data Science.
Read more →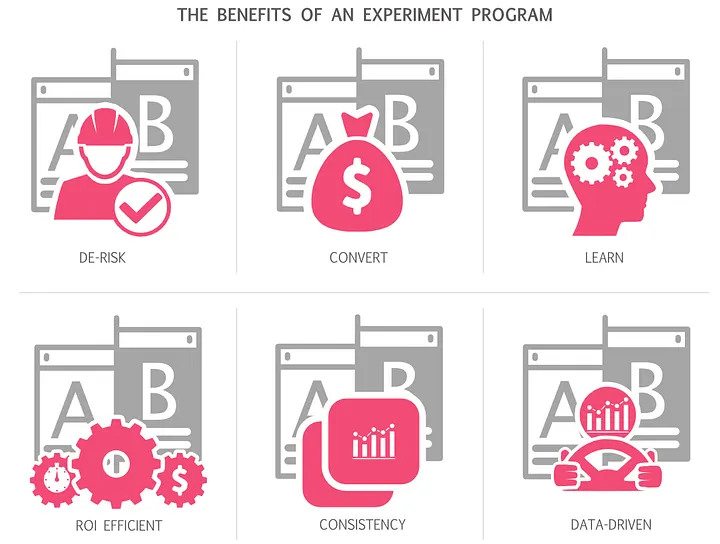
2/6/2021
The case for experimentation—shortcomings of intuition, user research, and pre/post analysis; what experiments and experiment programs actually deliver. Published in UX Collective.
Read more →
11/30/2020
An early-warning process for stopping experiments when something’s wrong—traffic split, missing traffic, or health metrics. No stats required. Published in The Startup.
Read more →
9/27/2020
Why well-defined processes make experiments effective—illustrated with a drawing experiment (with vs without a process) and mapped to what makes experiments and programs work. Published in UX Collective.
Read more →8/31/2020
A simple process to decide which metrics to build before launch—list outcomes, brainstorm reasons, then map to metrics. So every test can yield actionable learning. Published in UX Collective.
Read more →
8/13/2020
Eight conversion levers to use in hypotheses and track across experiments—value proposition, clarity, friction, relevance, social proof, urgency/scarcity, authority, confidence. Published in UX Collective.
Read more →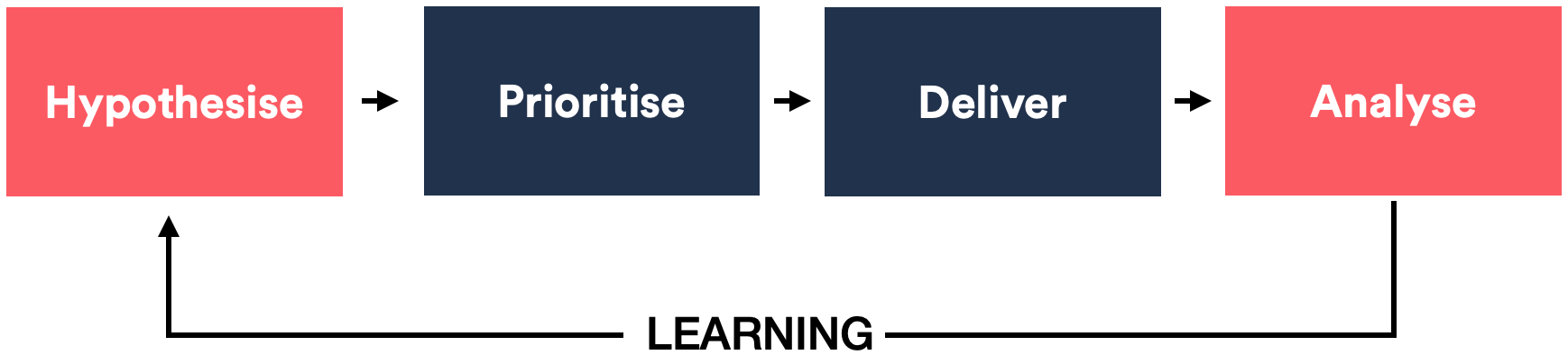
5/11/2020
A framework for bundling many changes into experiments without losing learning—hypotheses, justifications, secondary metrics, and when to bundle vs isolate. Published in UX Collective.
Read more →
12/14/2018
Why “who we count” into an experiment matters—assignment vs counting, test criteria, and three examples from simple page-level to feature-level. Published on The Trainline Blog.
Read more →