
A Beginner's Guide to AI Automation with n8n
11/10/2025
Step-by-step guide to building AI workflows with n8n and your local Ollama model. No coding required. Published on Convert.
Read more → 11/10/2025
Step-by-step guide to building AI workflows with n8n and your local Ollama model. No coding required. Published on Convert.
Read more →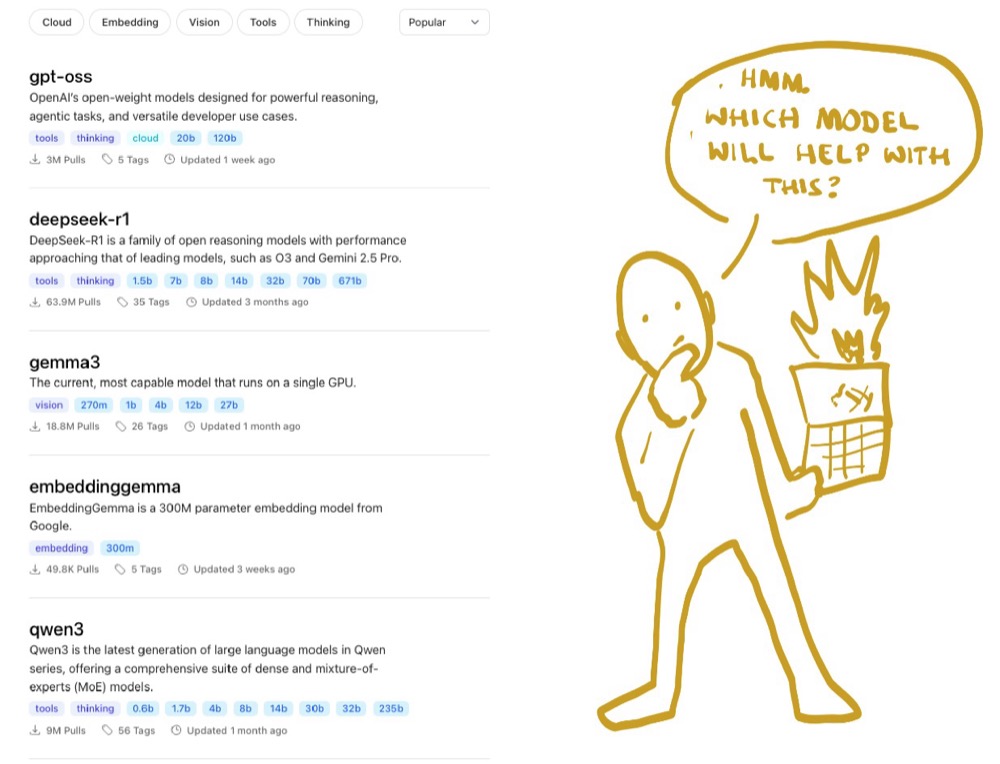
10/27/2025
Set up one chat interface to compare local and cloud AI models side by side. Uses Open WebUI, Docker, Ollama, and OpenRouter. Published on Convert.
Read more →
10/13/2025
Expose your LLM as an API so other apps and workflows can use it. Covers LM Studio Developer Mode and Ollama in the terminal. Published on Convert.
Read more →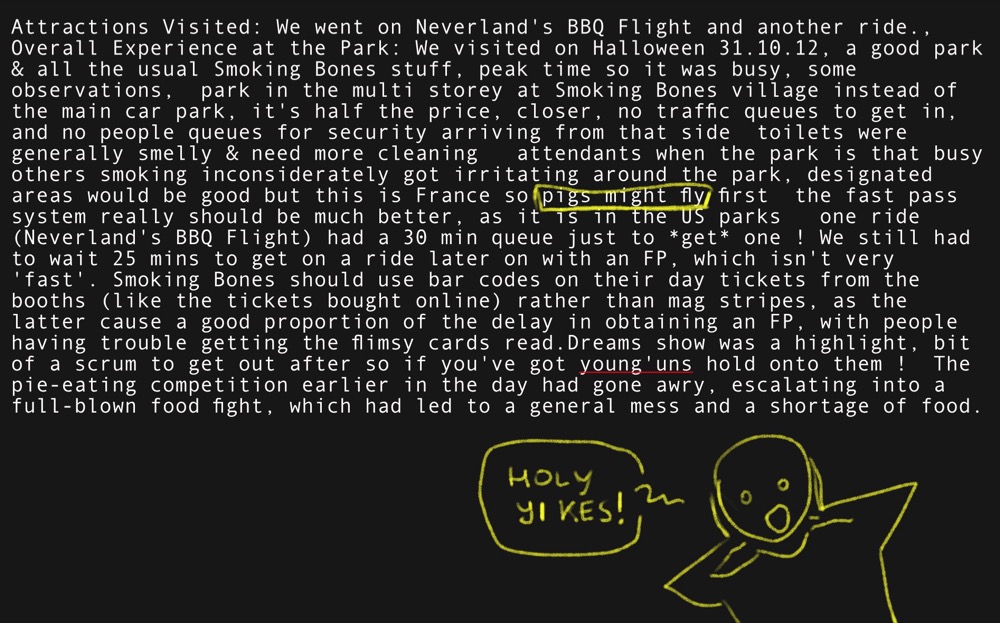
9/24/2025
How to get a tiny 0.6B model to match ChatGPT on messy user feedback—using “breakpoints” and splitting the task by sentiment. Published on Convert.
Read more →
9/10/2025
Why run small models on your own machine, and how to use LM Studio to find and test them on real tasks. Published on Convert.
Read more →
8/6/2025
What the “how many R’s in strawberry?” moment teaches us about LLMs—and five practical ways to use AI more clearly and responsibly. Published on Convert.
Read more →
6/26/2025
What AI hallucinations are, why they happen, and four practical ways to spot and manage them. Published on Convert.
Read more →
5/19/2025
Why “huge context” isn’t enough for text analysis—and simple ways to structure and filter your data so AI gives better, more reliable insights. Published on Convert.
Read more →
5/7/2025
My talk at Bristol Convert meetup...
Read more →
4/24/2025
Use one-shot and few-shot examples to steer attention, remove ambiguity, and get the format and tone you want. Published on Convert.
Read more →
3/26/2025
Share how you work with AI by naming “beats” (Query, Validate, Think, etc.) and chaining them into patterns—for research, brainstorming, and critique. Published on Convert.
Read more →
2/20/2025
Frameworks so AI supports your work instead of taking over—scaffolding, milestones, three modes of collaboration, and the Kolb learning cycle. Published on Convert.
Read more →1/22/2025
A visual guide to the stats you need for A/B tests—noise, standard deviation, z-scores, and p-values—so you can read results with confidence. Published on Convert.
Read more →
1/15/2025
Guest appearance on No Hacks discussing product development, solopreneurship, and how AI is reshaping the game for small teams and individuals.
Read more →
1/1/2025
Free playbook from Convert—practical AI guides for research, discovery, hypotheses, and copywriting. Made by experimenters, with 60+ prompts and real-dataset testing.
Read more →1/1/2025
When and where the weekly GRO Roundtable runs. Every Friday—Europe and US-friendly times. Sign up to join.
Read more →
1/1/2025
Bite-sized podcast summarizing GRO Roundtable discussions on growth, research, and optimization. Co-hosted with Matt Beischel.
Read more →
1/1/2025
A weekly, casual conversation about experimentation—no sales pitch, no formal presentations, no recording. Open to all CRO and experimentation practitioners.
Read more →
12/11/2024
My talk at London's Experimentation Elite...
Read more →9/6/2024
Podcast with Experiment Nation on solution bias—why we jump to solutions before we understand the problem, and how to use AI to explore the problem landscape and keep problem and solution connected.
Read more →
5/21/2024
With Craig Sullivan on No Hacks—practical applications of generative AI for UX, CRO, and experimentation, and how to keep the human element at the forefront.
Read more →
4/20/2022
Using simulations to answer when to run SRM checks, false-positive risk, optimal traffic for accuracy, and whether continuous monitoring increases Type I error. Published in Towards Data Science.
Read more →
7/22/2021
What SRM is, why it matters, and how to check it—with the Chi-squared test in Python and spreadsheets. Prioritise users over visits; check early and often. Published in Towards Data Science.
Read more →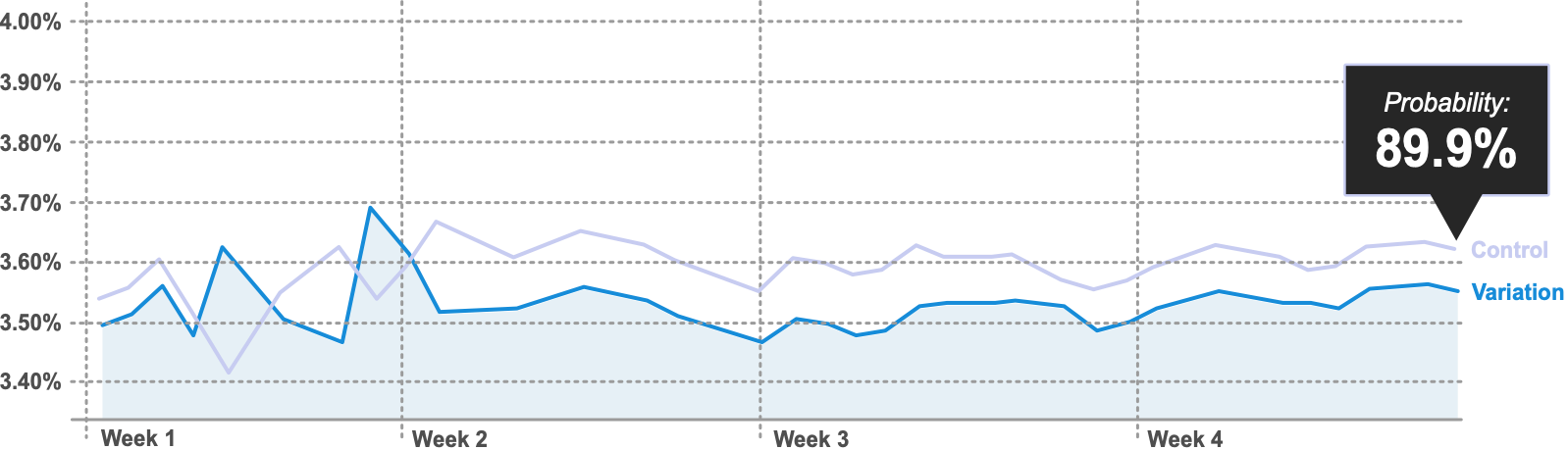
4/16/2021
A how-to for calculating Bayesian Expected Loss—the risk of choosing one variant over another—with Python, beta distributions, and rules for when to call a result. Published in Towards Data Science.
Read more →
3/2/2021
Telling the story of risk, reward, and certainty using the principles of comic panel transitions—and how Expected Loss adds a clearer, more actionable view. Published in Towards Data Science.
Read more →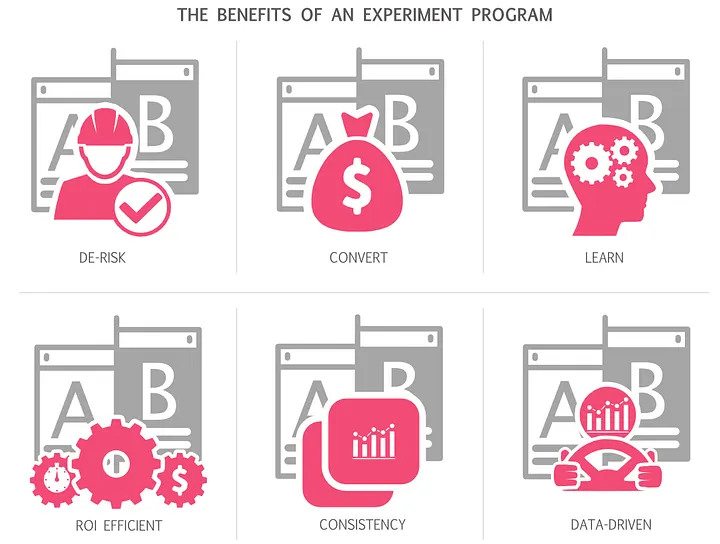
2/6/2021
The case for experimentation—shortcomings of intuition, user research, and pre/post analysis; what experiments and experiment programs actually deliver. Published in UX Collective.
Read more →
11/30/2020
An early-warning process for stopping experiments when something’s wrong—traffic split, missing traffic, or health metrics. No stats required. Published in The Startup.
Read more →
9/27/2020
Why well-defined processes make experiments effective—illustrated with a drawing experiment (with vs without a process) and mapped to what makes experiments and programs work. Published in UX Collective.
Read more →8/31/2020
A simple process to decide which metrics to build before launch—list outcomes, brainstorm reasons, then map to metrics. So every test can yield actionable learning. Published in UX Collective.
Read more →
8/13/2020
Eight conversion levers to use in hypotheses and track across experiments—value proposition, clarity, friction, relevance, social proof, urgency/scarcity, authority, confidence. Published in UX Collective.
Read more →
7/3/2020
How does one scale themselves to avoid becoming a bottleneck? I had this problem and experimented with a solution to resolve this. In this article, I describe the process along with details on how it went...
Read more →
5/11/2020
A framework for bundling many changes into experiments without losing learning—hypotheses, justifications, secondary metrics, and when to bundle vs isolate. Published in UX Collective.
Read more →
5/11/2020
Testing big is sometimes necessary. I've written a detailed guide about how to go about it successfully...
Read more →1/1/2020
Visualise A/B test results as risk and reward charts. Make decisions with greater clarity using data validity checks and trended results.
Read more →
12/14/2018
Why “who we count” into an experiment matters—assignment vs counting, test criteria, and three examples from simple page-level to feature-level. Published on The Trainline Blog.
Read more →